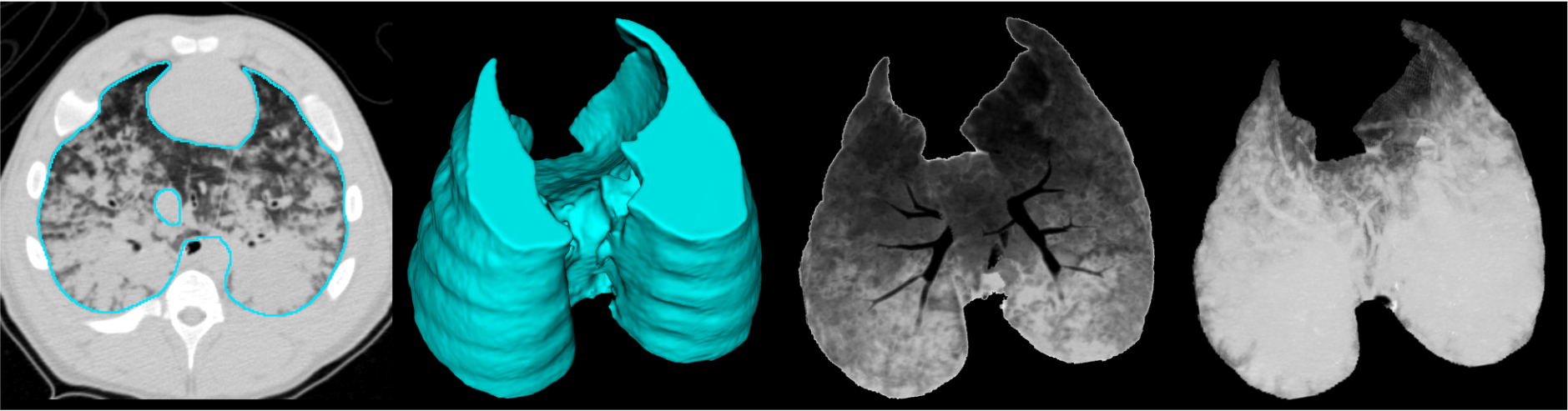
Artificial intelligence (AI) enables machines to learn patterns from data to automatically perform human-like tasks. Deep learning is a branch of AI that uses deep neural networks to learn relationships directly from raw data, such as images. Deep learning has been highly successful at analyzing image data and has achieved human-level accuracy at tasks such as image classification, segmentation, detection, and translation. We specialize in developing deep learning algorithms for analyzing volumetric medical images of the lungs by overcoming challenges imposed by large 3D datasets, complex structures, uncertainty, and limited labeled training data.
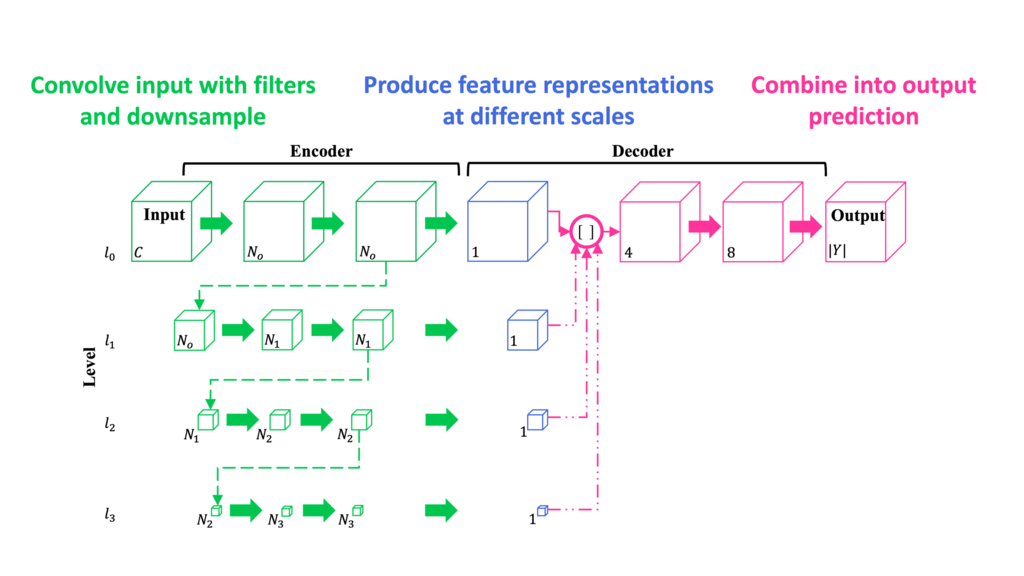
Seg3DNet
A convolutional neural network (CNN) is a type of deep neural network that is designed to exploit the highly correlated information in images.
A CNN consists of a hierarchy of layers where in each layer the input image is convolved with small filters to produce and output activation image. The filter values are the parameters that are optimized during training.
We designed Seg3DNet which is a memory efficient 3D CNN designed for processing volumetric medical images.
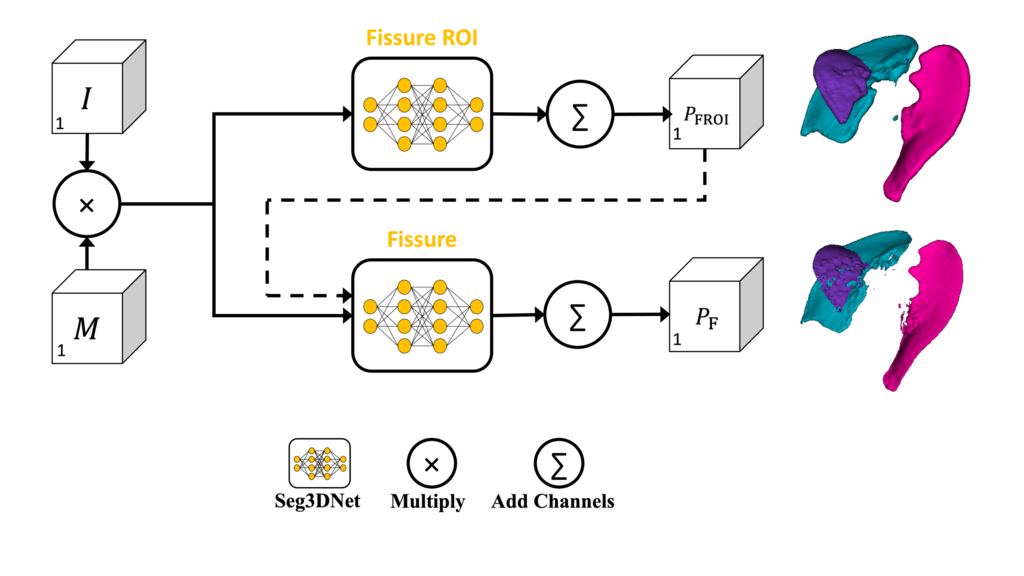
FissureNet
The pulmonary fissures are very thin single-voxel surfaces that account for less than 1% of voxels in a pulmonary CT image. This creates a large class imbalance between fissure and non-fissure classes making fissure detection a very challenging problem.
We proposed FissureNet first detects a fissure region of interest (ROI) and then refines the precise fissure location within the ROI. This alleviates the class imbalance and improves detection of weak and fuzzy fissures.
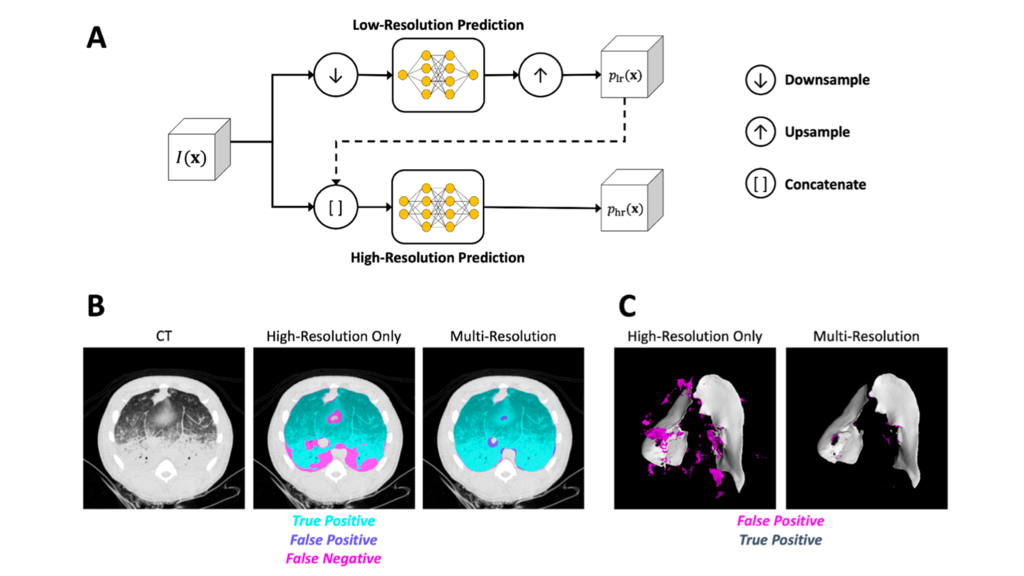
Cascaded Multi-Res CNNs
Efficient training of neural networks requires GPUs which have a limited amount of memory. Typically training is performed on extracted 2D slices or small 3D subregions, however, this prevents the network from learning 3D and global contextual features.
Global and local information is important for understanding information in medical images. We proposed cascaded multi-resolution CNNs for learning global and local information with GPU memory constraints. Two CNNs, each utilizing the Seg3DNet architecture, are trained with the output of the first low-resolution network used as input to the second high-resolution network.
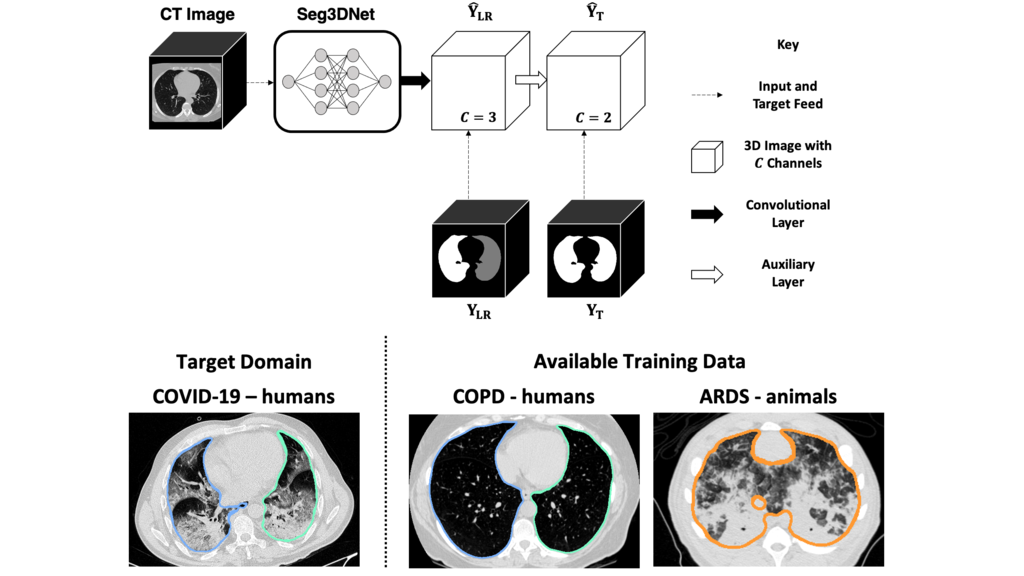
Polymorphic Training
Deep neural networks thrive on large training datasets which imposes a challenge for medical imaging. Producing ground truth labels is time-consuming, subjective, and requires a medical expert.
We proposed a polymorphic training paradigm which utilizes training data with different levels of label specificity to allow segmentation in the target domain with the highest label specificity.
We used cascaded multi-resolution CNNs (each utilizing Seg3DNet) in a polymorphic training paradigm to achieve lung and segmentation in COVID-19 subjects without using any labeled training data from COVID-19 subjects.